Bias Measurement
The following guide is designed to present the more general details on using the package to measure bias. The following sections show:
how to run a simple query using
Gloveembedding model.how to run multiple queries on multiple embeddings.
how to compare the results obtained from running multiple sets of queries on multiple embeddings using different metrics through ranking calculation.
how to calculate the correlations between the rankings obtained.
Warning
To accurately study and reduce biases contained in word embeddings, queries may contain words that could be offensive to certain groups or individuals. The relationships studied between these words DO NOT represent the ideas, thoughts or beliefs of the authors of this library. This warning applies to all documentation.
Note
If you are not familiar with the concepts of query, target and attribute set, please visit the Measurement Framework on the library’s conceptual guides. These concepts are widely used in the following sections.
Note
For a list of metrics implemented in WEFE, refer to the metrics section of the API reference.
Run a Query
The following subsections explains how to run a simple query that
measures gender bias on
Glove.
The example uses the Word Embedding Association Test (WEAT)
metric quantifying the bias in the embeddings model. Below we show the three usual
steps for performing a query in WEFE:
Note
WEAT is a fairness metric that quantifies the relationship
between two sets of target words (sets of words intended to denote a social
groups as men and women) and two sets of attribute words (sets of words
representing some attitude, characteristic, trait, occupational field,
etc. that can be associated with individuals from any social group).
The closer its value is to 0, the less biased the model is.
Visit the metrics documentation (WEAT) for more information.
Load a word embeddings model as a WordEmbeddingModel object
Load the word embedding model and then wrap it using a
WordEmbeddingModel (class that allows WEFE to handle the models).
WEFE bases all its operations on word embeddings using Gensim’s
KeyedVectors interface. Any model that can be loaded using
KeyedVectors will be compatible with WEFE. The following example uses a 25-dim pre-trained Glove model using a
twitter dataset loaded using gensim-data.
Note
Visit gensim-data repository. to find the complete list of published pre-trained models ready to use.
import gensim.downloader as api
from wefe.datasets import load_weat
from wefe.metrics import WEAT
from wefe.query import Query
from wefe.word_embedding_model import WordEmbeddingModel
twitter_25 = api.load("glove-twitter-25")
# WordEmbeddingModel receives as first argument a KeyedVectors model
# and the second argument the model name.
model = WordEmbeddingModel(twitter_25, "glove twitter dim=25")
Create the query using a Query object
Define the target and attribute word sets and create a Query object
that contains them.
For this initial example, a query is used to study the association
between gender with respect to family and career. The words used are
taken from the set of words used in the Semantics derived automatically
from language corpora contain human-like biases paper, which are
included in the datasets module.
gender_query = Query(
target_sets=[
["female", "woman", "girl", "sister", "she", "her", "hers", "daughter"],
["male", "man", "boy", "brother", "he", "him", "his", "son"],
],
attribute_sets=[
[
"home",
"parents",
"children",
"family",
"cousins",
"marriage",
"wedding",
"relatives",
],
[
"executive",
"management",
"professional",
"corporation",
"salary",
"office",
"business",
"career",
],
],
target_sets_names=["Female terms", "Male Terms"],
attribute_sets_names=["Family", "Careers"],
)
gender_query
<Query: Female terms and Male Terms wrt Family and Careers
- Target sets: [['female', 'woman', 'girl', 'sister', 'she', 'her', 'hers', 'daughter'], ['male', 'man', 'boy', 'brother', 'he', 'him', 'his', 'son']]
- Attribute sets:[['home', 'parents', 'children', 'family', 'cousins', 'marriage', 'wedding', 'relatives'], ['executive', 'management', 'professional', 'corporation', 'salary', 'office', 'business', 'career']]>
Run the Query
Instantiate the metric that you will use and then execute run_query
with the parameters created in the previous steps.
Any bias measurement process at WEFE consists of the following steps:
Metric arguments checking.
Transform the word sets into word embeddings.
Calculate the metric.
In this case we use the WEAT metric (proposed in the
same paper of the set of words used in the query).
metric = WEAT()
result = metric.run_query(gender_query, model)
result
{'query_name': 'Female terms and Male Terms wrt Family and Careers',
'result': 0.31658412935212255,
'weat': 0.31658412935212255,
'effect_size': 0.6779439085309583,
'p_value': nan}
By default, the results are a dict containing the query name (in the
key query_name) and the calculated value of the metric in the
result key. It also contains a key with the name and the value of
the calculated metric (which is duplicated in the “results” key).
Depending on the metric class used, the result dict can also return
more metrics, detailed word-by-word values or other statistics like
p-values. Also some metrics allow you to change the default value in
results.
Details of all the metrics implemented, their parameters and examples of execution can be found at metrics section.
Run Query Arguments
Each metric allows varying the behavior of run_query according to
different parameters. There are parameters to customize the
transformation of the sets of words to sets of embeddings, others to
warn errors or modify which calculation method the metric use.
Note
Each metric implements the run_query method with different arguments.
Visit their API documentation for more information.
For example, run_query can be instructed to return effect_size
in the result key by setting return_effect_size as True.
Note that this parameter is only of the class WEAT`.
weat = WEAT()
result = weat.run_query(gender_query, model, return_effect_size=True)
result
{'query_name': 'Female terms and Male Terms wrt Family and Careers',
'result': 0.6779439085309583,
'weat': 0.31658412935212255,
'effect_size': 0.6779439085309583,
'p_value': nan}
You can also request run_query to run the statistical significance
calculation by setting calculate_p_value as True. This checks
how many queries generated from permutations (controlled by the
parameter p_value_iterations) of the target sets obtain values
greater than those obtained by the original query.
weat = WEAT()
result = weat.run_query(
gender_query, model, calculate_p_value=True, p_value_iterations=5000
)
result
{'query_name': 'Female terms and Male Terms wrt Family and Careers',
'result': 0.31658412935212255,
'weat': 0.31658412935212255,
'effect_size': 0.6779439085309583,
'p_value': 0.08418316336732654}
Out of Vocabulary Words and Word Preprocessors
It is common in the literature to find bias tests whose tagret sets are
common names of social groups. These names are commonly cased and may
contain special characters. There are several embedding models whose
words are not cased or do not have accents or other special characters,
as for example, in Glove. This implies that a query with target sets
composed by names executed in Glove (without any preprocessing of
the words) could produce erroneous results because WEFE will not be able
to find the names in the model vocabulary.
Note
Some well-known word sets are already provided by the package and can be
easily loaded by the user through the datasets module. From here on,
the tutorial use the words defined in the study Semantics derived
automatically from language corpora contain human-like biases, the same
that proposed the WEAT metric.
# load the weat word sets.
word_sets = load_weat()
# print a set of european american common names.
print(word_sets["european_american_names_5"])
['Adam', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Justin', 'Ryan', 'Andrew', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Paul', 'Jonathan', 'Peter', 'Amanda', 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Katie', 'Betsy', 'Kristin', 'Nancy', 'Stephanie', 'Ellen', 'Lauren', 'Colleen', 'Emily', 'Megan', 'Rachel']
The following query compares European-American and African-American names with respect to pleasant and unpleasant attributes.
Note
It can be indicated to run_query to log the words that were lost in
the transformation to vectors by using the parameter
warn_not_found_words as True.
ethnicity_query = Query(
[word_sets["european_american_names_5"], word_sets["african_american_names_5"]],
[word_sets["pleasant_5"], word_sets["unpleasant_5a"]],
["European american names", "African american names"],
["Pleasant", "Unpleasant"],
)
result = weat.run_query(ethnicity_query, model, warn_not_found_words=True,)
result
WARNING:root:The following words from set 'European american names' do not exist within the vocabulary of glove twitter dim=25: ['Adam', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Justin', 'Ryan', 'Andrew', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Paul', 'Jonathan', 'Peter', 'Amanda', 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Katie', 'Betsy', 'Kristin', 'Nancy', 'Stephanie', 'Ellen', 'Lauren', 'Colleen', 'Emily', 'Megan', 'Rachel']
WARNING:root:The transformation of 'European american names' into glove twitter dim=25 embeddings lost proportionally more words than specified in 'lost_words_threshold': 1.0 lost with respect to 0.2 maximum loss allowed.
WARNING:root:The following words from set 'African american names' do not exist within the vocabulary of glove twitter dim=25: ['Alonzo', 'Jamel', 'Theo', 'Alphonse', 'Jerome', 'Leroy', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Lavon', 'Marcellus', 'Wardell', 'Nichelle', 'Shereen', 'Ebony', 'Latisha', 'Shaniqua', 'Jasmine', 'Tanisha', 'Tia', 'Lakisha', 'Latoya', 'Yolanda', 'Malika', 'Yvette']
WARNING:root:The transformation of 'African american names' into glove twitter dim=25 embeddings lost proportionally more words than specified in 'lost_words_threshold': 1.0 lost with respect to 0.2 maximum loss allowed.
ERROR:root:At least one set of 'European american names and African american names wrt Pleasant and Unpleasant' query has proportionally fewer embeddings than allowed by the lost_vocabulary_threshold parameter (0.2). This query will return np.nan.
{'query_name': 'European american names and African american names wrt Pleasant and Unpleasant',
'result': nan,
'weat': nan,
'effect_size': nan}
Warning
If more than 20% of the words from any of the word sets of the query are
lost during the transformation to embeddings, the result of the metric
will be np.nan. This behavior can be changed using a float number
parameter called lost_vocabulary_threshold.
Word Preprocessors
Any run_query method allows preprocessing each word before they are searched in the model’s
vocabulary through the parameter preprocessors (list of one or more preprocessor).
This parameter accepts a list of individual preprocessors, which are defined below:
A preprocessor is a dictionary that specifies what processing(s) are
performed on each word before its looked up in the model vocabulary.
For example, the preprocessor
{'lowecase': True, 'strip_accents': True} allows you to lowercase
and remove the accent from each word before searching for them in the
model vocabulary. Note that an empty dictionary {} indicates that no
preprocessing is done.
The possible options for a preprocessor are:
lowercase:bool. Indicates that the words are transformed to lowercase.uppercase:bool. Indicates that the words are transformed to uppercase.titlecase:bool. Indicates that the words are transformed to titlecase.strip_accents:bool,{'ascii', 'unicode'}: Specifies that the accents of the words are eliminated. The stripping type can be specified. True uses ‘unicode’ by default.preprocessor:Callable. It receives a function that operates on each word. In the case of specifying a function, it overrides the default preprocessor (i.e., the previous options stop working).
A list of preprocessor options allows searching for several
variants of the words into the model. For example, the preprocessors
[{}, {"lowercase": True, "strip_accents": True}]
{} allows searching first for the original words in the vocabulary of the model.
In case some of them are not found, {"lowercase": True, "strip_accents": True}
is executed on these words and then they are searched in the model vocabulary.
By default (in case there is more than one preprocessor in the list) the first
preprocessed word found in the embeddings model is used.
This behavior can be controlled by the strategy parameter of run_query.
In the following example, we provide a list with only one
preprocessor that instructs run_query to lowercase and remove all
accents from every word before they are searched in the embeddings
model.
weat = WEAT()
result = weat.run_query(
ethnicity_query,
model,
preprocessors=[{"lowercase": True, "strip_accents": True}],
warn_not_found_words=True,
)
result
WARNING:root:The following words from set 'African american names' do not exist within the vocabulary of glove twitter dim=25: ['wardell']
{'query_name': 'European american names and African american names wrt Pleasant and Unpleasant',
'result': 3.7529150679125456,
'weat': 3.7529150679125456,
'effect_size': 1.2746819330405683,
'p_value': nan}
It may happen that it is more important to find the original word and in
the case of not finding it, then preprocess it and look it up in the
vocabulary. This behavior can be specified in preprocessors list by
first specifying an empty preprocessor {} and then the preprocessor
that converts to lowercase and removes accents.
weat = WEAT()
result = weat.run_query(
ethnicity_query,
model,
preprocessors=[
{}, # empty preprocessor, search for the original words.
{
"lowercase": True,
"strip_accents": True,
}, # search for lowercase and no accent words.
],
warn_not_found_words=True,
)
result
WARNING:root:The following words from set 'European american names' do not exist within the vocabulary of glove twitter dim=25: ['Adam', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Justin', 'Ryan', 'Andrew', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Paul', 'Jonathan', 'Peter', 'Amanda', 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Katie', 'Betsy', 'Kristin', 'Nancy', 'Stephanie', 'Ellen', 'Lauren', 'Colleen', 'Emily', 'Megan', 'Rachel']
WARNING:root:The following words from set 'African american names' do not exist within the vocabulary of glove twitter dim=25: ['Alonzo', 'Jamel', 'Theo', 'Alphonse', 'Jerome', 'Leroy', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Lavon', 'Marcellus', 'Wardell', 'wardell', 'Nichelle', 'Shereen', 'Ebony', 'Latisha', 'Shaniqua', 'Jasmine', 'Tanisha', 'Tia', 'Lakisha', 'Latoya', 'Yolanda', 'Malika', 'Yvette']
{'query_name': 'European american names and African american names wrt Pleasant and Unpleasant',
'result': 3.7529150679125456,
'weat': 3.7529150679125456,
'effect_size': 1.2746819330405683,
'p_value': nan}
The number of preprocessing steps can be increased as needed. For example, we can complex the above preprocessor to first search for the original words, then for the lowercase words, and finally for the lowercase words without accents.
weat = WEAT()
result = weat.run_query(
ethnicity_query,
model,
preprocessors=[
{}, # first step: empty preprocessor, search for the original words.
{"lowercase": True,}, # second step: search for lowercase.
{
"lowercase": True,
"strip_accents": True,
}, # third step: search for lowercase and no accent words.
],
warn_not_found_words=True,
)
result
WARNING:root:The following words from set 'European american names' do not exist within the vocabulary of glove twitter dim=25: ['Adam', 'Harry', 'Josh', 'Roger', 'Alan', 'Frank', 'Justin', 'Ryan', 'Andrew', 'Jack', 'Matthew', 'Stephen', 'Brad', 'Greg', 'Paul', 'Jonathan', 'Peter', 'Amanda', 'Courtney', 'Heather', 'Melanie', 'Sara', 'Amber', 'Katie', 'Betsy', 'Kristin', 'Nancy', 'Stephanie', 'Ellen', 'Lauren', 'Colleen', 'Emily', 'Megan', 'Rachel']
WARNING:root:The following words from set 'African american names' do not exist within the vocabulary of glove twitter dim=25: ['Alonzo', 'Jamel', 'Theo', 'Alphonse', 'Jerome', 'Leroy', 'Torrance', 'Darnell', 'Lamar', 'Lionel', 'Tyree', 'Deion', 'Lamont', 'Malik', 'Terrence', 'Tyrone', 'Lavon', 'Marcellus', 'Wardell', 'wardell', 'wardell', 'Nichelle', 'Shereen', 'Ebony', 'Latisha', 'Shaniqua', 'Jasmine', 'Tanisha', 'Tia', 'Lakisha', 'Latoya', 'Yolanda', 'Malika', 'Yvette']
{'query_name': 'European american names and African american names wrt Pleasant and Unpleasant',
'result': 3.7529150679125456,
'weat': 3.7529150679125456,
'effect_size': 1.2746819330405683,
'p_value': nan}
It is also possible to change the behavior of the search by including
not only the first word, but all the words generated by the
preprocessors. This can be controlled by specifying the parameter
strategy=all.
weat = WEAT()
result = weat.run_query(
ethnicity_query,
model,
preprocessors=[
{}, # first step: empty preprocessor, search for the original words.
{"lowercase": True,}, # second step: search for lowercase .
{"uppercase": True,}, # third step: search for uppercase.
],
strategy="all",
warn_not_found_words=True,
)
result
WARNING:root:The following words from set 'European american names' do not exist within the vocabulary of glove twitter dim=25: ['Adam', 'ADAM', 'Harry', 'HARRY', 'Josh', 'JOSH', 'Roger', 'ROGER', 'Alan', 'ALAN', 'Frank', 'FRANK', 'Justin', 'JUSTIN', 'Ryan', 'RYAN', 'Andrew', 'ANDREW', 'Jack', 'JACK', 'Matthew', 'MATTHEW', 'Stephen', 'STEPHEN', 'Brad', 'BRAD', 'Greg', 'GREG', 'Paul', 'PAUL', 'Jonathan', 'JONATHAN', 'Peter', 'PETER', 'Amanda', 'AMANDA', 'Courtney', 'COURTNEY', 'Heather', 'HEATHER', 'Melanie', 'MELANIE', 'Sara', 'SARA', 'Amber', 'AMBER', 'Katie', 'KATIE', 'Betsy', 'BETSY', 'Kristin', 'KRISTIN', 'Nancy', 'NANCY', 'Stephanie', 'STEPHANIE', 'Ellen', 'ELLEN', 'Lauren', 'LAUREN', 'Colleen', 'COLLEEN', 'Emily', 'EMILY', 'Megan', 'MEGAN', 'Rachel', 'RACHEL']
WARNING:root:The following words from set 'African american names' do not exist within the vocabulary of glove twitter dim=25: ['Alonzo', 'ALONZO', 'Jamel', 'JAMEL', 'Theo', 'THEO', 'Alphonse', 'ALPHONSE', 'Jerome', 'JEROME', 'Leroy', 'LEROY', 'Torrance', 'TORRANCE', 'Darnell', 'DARNELL', 'Lamar', 'LAMAR', 'Lionel', 'LIONEL', 'Tyree', 'TYREE', 'Deion', 'DEION', 'Lamont', 'LAMONT', 'Malik', 'MALIK', 'Terrence', 'TERRENCE', 'Tyrone', 'TYRONE', 'Lavon', 'LAVON', 'Marcellus', 'MARCELLUS', 'Wardell', 'wardell', 'WARDELL', 'Nichelle', 'NICHELLE', 'Shereen', 'SHEREEN', 'Ebony', 'EBONY', 'Latisha', 'LATISHA', 'Shaniqua', 'SHANIQUA', 'Jasmine', 'JASMINE', 'Tanisha', 'TANISHA', 'Tia', 'TIA', 'Lakisha', 'LAKISHA', 'Latoya', 'LATOYA', 'Yolanda', 'YOLANDA', 'Malika', 'MALIKA', 'Yvette', 'YVETTE']
WARNING:root:The following words from set 'Pleasant' do not exist within the vocabulary of glove twitter dim=25: ['CARESS', 'FREEDOM', 'HEALTH', 'LOVE', 'PEACE', 'CHEER', 'FRIEND', 'HEAVEN', 'LOYAL', 'PLEASURE', 'DIAMOND', 'GENTLE', 'HONEST', 'LUCKY', 'RAINBOW', 'DIPLOMA', 'GIFT', 'HONOR', 'MIRACLE', 'SUNRISE', 'FAMILY', 'HAPPY', 'LAUGHTER', 'PARADISE', 'VACATION']
WARNING:root:The following words from set 'Unpleasant' do not exist within the vocabulary of glove twitter dim=25: ['ABUSE', 'CRASH', 'FILTH', 'MURDER', 'SICKNESS', 'ACCIDENT', 'DEATH', 'GRIEF', 'POISON', 'STINK', 'ASSAULT', 'DISASTER', 'HATRED', 'POLLUTE', 'TRAGEDY', 'DIVORCE', 'JAIL', 'POVERTY', 'UGLY', 'CANCER', 'KILL', 'ROTTEN', 'VOMIT', 'AGONY', 'PRISON']
{'query_name': 'European american names and African american names wrt Pleasant and Unpleasant',
'result': 3.7529150679125456,
'weat': 3.7529150679125456,
'effect_size': 1.2746819330405683,
'p_value': nan}
Running Multiple Queries
It is usual to want to test many queries of some bias criterion (gender,
ethnicity, religion, politics, socioeconomic, among others) on several
models at the same time. Trying to use run_query on each pair
embedding-query can be a bit complex and could require extra work to
implement.
This is why WEFE also implements a function to test multiple
queries on various word embedding models in a single call: the
run_queries() util.
The following code shows how to run various gender queries on Glove
embedding models with different dimensions trained from the Twitter
dataset. The queries are executed using WEAT metric.
import gensim.downloader as api
from wefe.datasets import load_weat
from wefe.metrics import RNSB, WEAT
from wefe.query import Query
from wefe.utils import run_queries
from wefe.word_embedding_model import WordEmbeddingModel
Load the models
Load three different Glove Twitter embedding models. These models were trained using the same dataset varying the number of embedding dimensions.
model_1 = WordEmbeddingModel(api.load("glove-twitter-25"), "glove twitter dim=25")
model_2 = WordEmbeddingModel(api.load("glove-twitter-50"), "glove twitter dim=50")
model_3 = WordEmbeddingModel(api.load("glove-twitter-100"), "glove twitter dim=100")
models = [model_1, model_2, model_3]
Load the word sets and create the queries
Now, we load the WEAT word set and create three queries. The
three queries are intended to measure gender bias.
# Load the WEAT word sets
word_sets = load_weat()
# Create gender queries
gender_query_1 = Query(
[word_sets["male_terms"], word_sets["female_terms"]],
[word_sets["career"], word_sets["family"]],
["Male terms", "Female terms"],
["Career", "Family"],
)
gender_query_2 = Query(
[word_sets["male_terms"], word_sets["female_terms"]],
[word_sets["science"], word_sets["arts"]],
["Male terms", "Female terms"],
["Science", "Arts"],
)
gender_query_3 = Query(
[word_sets["male_terms"], word_sets["female_terms"]],
[word_sets["math"], word_sets["arts_2"]],
["Male terms", "Female terms"],
["Math", "Arts"],
)
gender_queries = [gender_query_1, gender_query_2, gender_query_3]
Run the queries on all Word Embeddings using WEAT
To run the list of queries and models, we call run_queries() using the
parameters defined in the previous step. The mandatory parameters of the
function are 3:
a metric,
a list of queries, and,
a list of embedding models.
It is also possible to provide a name for the criterion studied in this
set of queries through the parameter queries_set_name.
WEAT_gender_results = run_queries(
WEAT, gender_queries, models, queries_set_name="Gender Queries"
)
WEAT_gender_results
WARNING:root:The transformation of 'Science' into glove twitter dim=25 embeddings lost proportionally more words than specified in 'lost_words_threshold': 0.25 lost with respect to 0.2 maximum loss allowed.
ERROR:root:At least one set of 'Male terms and Female terms wrt Science and Arts' query has proportionally fewer embeddings than allowed by the lost_vocabulary_threshold parameter (0.2). This query will return np.nan.
WARNING:root:The transformation of 'Science' into glove twitter dim=50 embeddings lost proportionally more words than specified in 'lost_words_threshold': 0.25 lost with respect to 0.2 maximum loss allowed.
ERROR:root:At least one set of 'Male terms and Female terms wrt Science and Arts' query has proportionally fewer embeddings than allowed by the lost_vocabulary_threshold parameter (0.2). This query will return np.nan.
WARNING:root:The transformation of 'Science' into glove twitter dim=100 embeddings lost proportionally more words than specified in 'lost_words_threshold': 0.25 lost with respect to 0.2 maximum loss allowed.
ERROR:root:At least one set of 'Male terms and Female terms wrt Science and Arts' query has proportionally fewer embeddings than allowed by the lost_vocabulary_threshold parameter (0.2). This query will return np.nan.
| query_name | Male terms and Female terms wrt Career and Family | Male terms and Female terms wrt Science and Arts | Male terms and Female terms wrt Math and Arts |
|---|---|---|---|
| model_name | |||
| glove twitter dim=25 | 0.316584 | NaN | -0.022133 |
| glove twitter dim=50 | 0.363743 | NaN | -0.272334 |
| glove twitter dim=100 | 0.385352 | NaN | -0.082544 |
Setting metric params
There is a whole column that has no results. As the warnings point out,
when transforming the words of the sets into embeddings, there is a loss
of words that is greater than the allowed by the parameter
lost_vocabulary_threshold. In this case, it would be very useful to
use the word preprocessors seen above.
run_queries(), accept specific parameters for each metric. These extra
parameters for the metric can be passed through metric_params
parameter. In this case, a preprocessor is provided to lowercase the
words before searching for them in the models’ vocabularies.
WEAT_gender_results = run_queries(
WEAT,
gender_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
queries_set_name="Gender Queries",
)
WEAT_gender_results
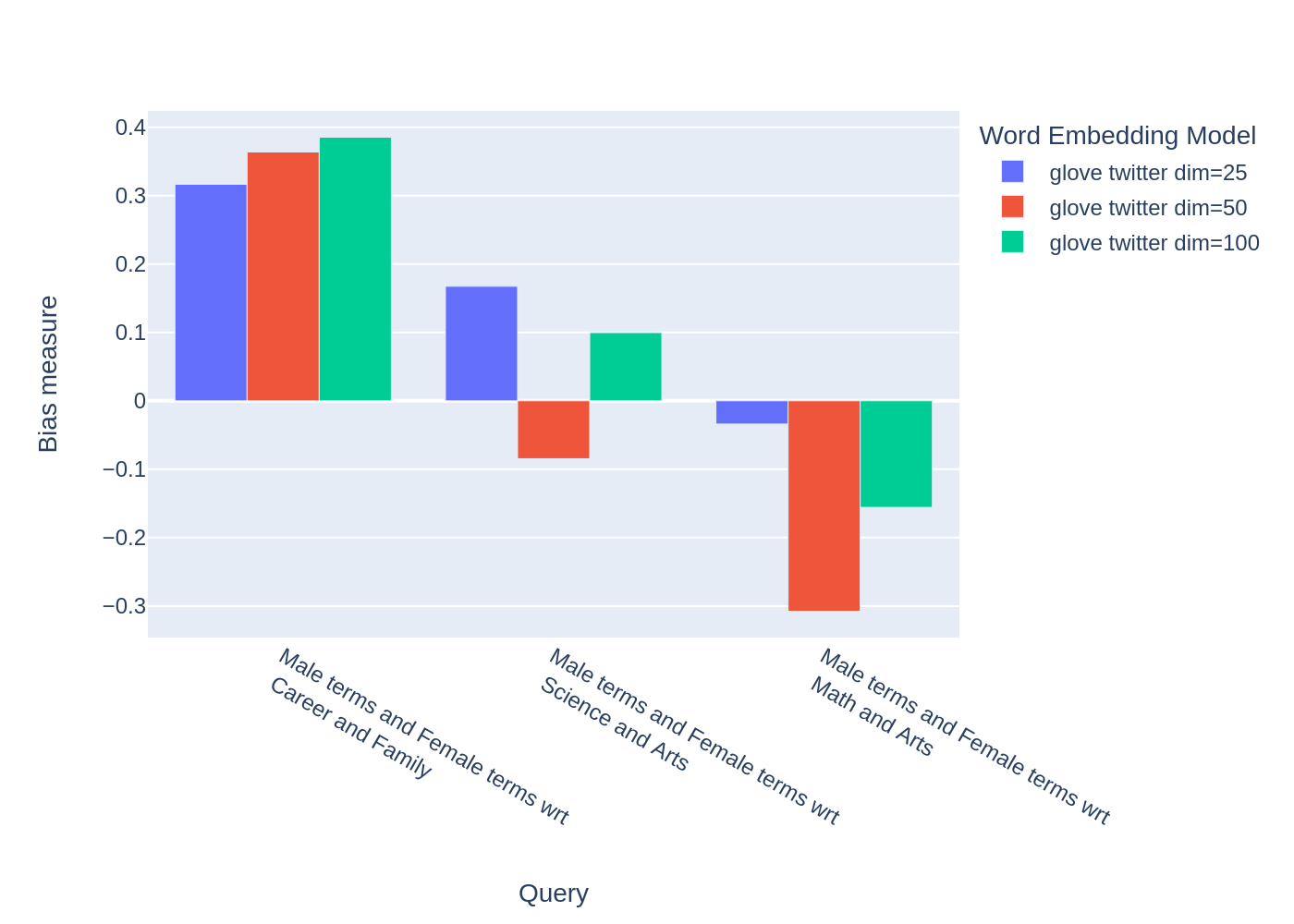
| query_name | Male terms and Female terms wrt Career and Family | Male terms and Female terms wrt Science and Arts | Male terms and Female terms wrt Math and Arts |
|---|---|---|---|
| model_name | |||
| glove twitter dim=25 | 0.316584 | 0.167431 | -0.033912 |
| glove twitter dim=50 | 0.363743 | -0.084690 | -0.307589 |
| glove twitter dim=100 | 0.385352 | 0.099632 | -0.155790 |
No query was null in these results.
Plot the results in a barplot
The library also provides an easy way to plot the results obtained from
a run_queries execution into a plotly barplot.
from wefe.utils import plot_queries_results, run_queries
# Plot the results
plot_queries_results(WEAT_gender_results).show()
Aggregating Results
The execution of run_queries() provided many results evaluating the
gender bias in the tested embeddings. However, these results alone do
not comprehensively report the biases observed in all of these queries.
One way to obtain an overall view of bias is by aggregating results by
model.
For WEAT, a simple way to aggregate the results is to average their
absolute values. When running run_queries(), it is possible to specify
that the results be aggregated by model by setting aggregate_results
as True
The aggregation function can be specified through the
aggregation_function parameter. This parameter accepts a list of
predefined aggregations as well as a custom function that operates on
the results dataframe. The aggregation functions available are:
Average
avg.Average of the absolute values
abs_avg.Sum
sum.Sum of the absolute values,
abs_sum.
Note
Notice that some functions are more appropriate for certain metrics. For
metrics returning only positive numbers, all the previous aggregation
functions would be OK. In contrast, metrics that return real values
(e.g., WEAT , RND , etc…),
aggregation functions such as sum would make positive and negative outputs to cancel
each other.
WEAT_gender_results_agg = run_queries(
WEAT,
gender_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
aggregate_results=True,
aggregation_function="abs_avg",
queries_set_name="Gender Queries",
)
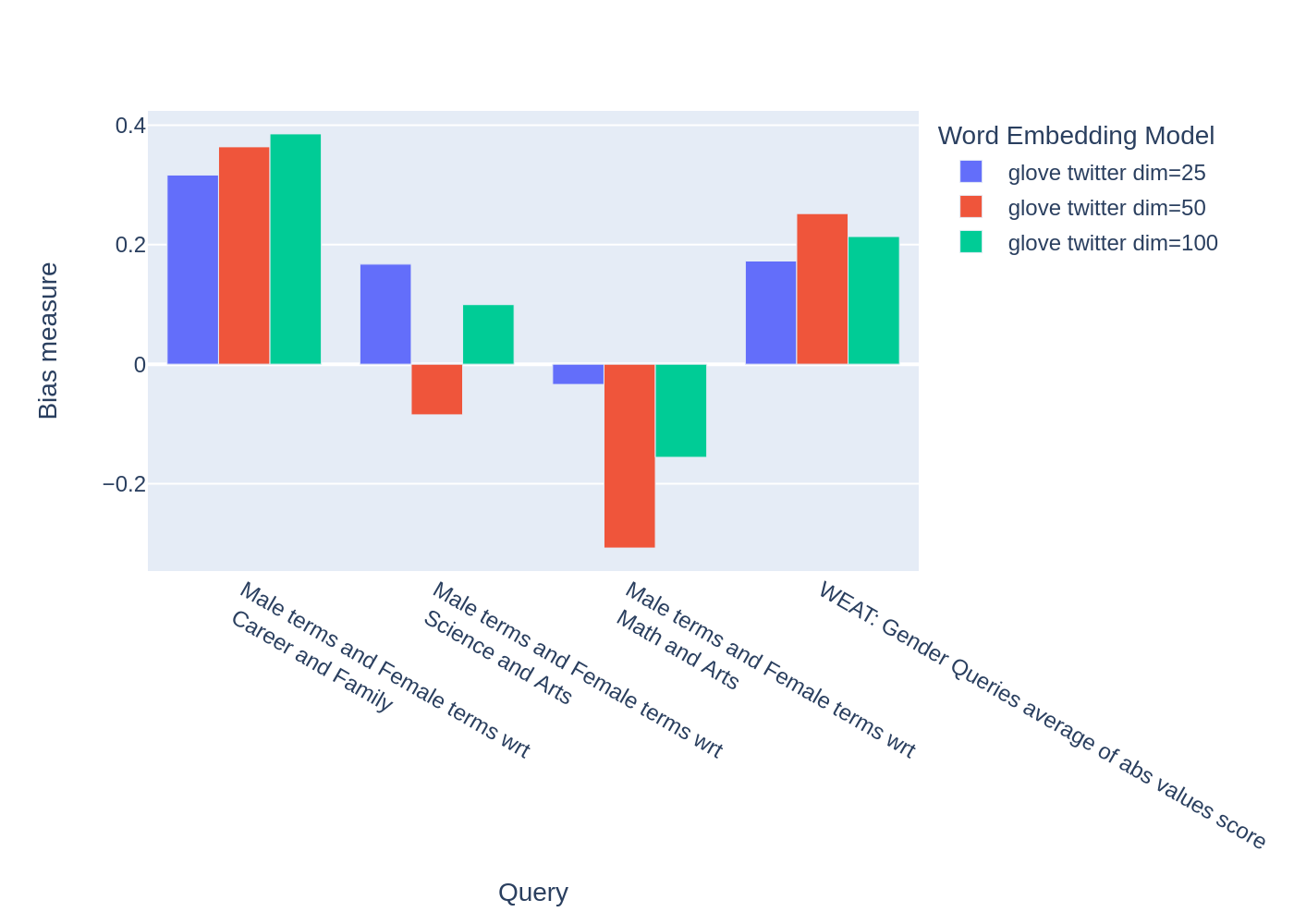
WEAT_gender_results_agg
| Male terms and Female terms wrt Career and Family | Male terms and Female terms wrt Science and Arts | Male terms and Female terms wrt Math and Arts | WEAT: Gender Queries average of abs values score | |
|---|---|---|---|---|
| model_name | ||||
| glove twitter dim=25 | 0.316584 | 0.167431 | -0.033912 | 0.172642 |
| glove twitter dim=50 | 0.363743 | -0.084690 | -0.307589 | 0.252007 |
| glove twitter dim=100 | 0.385352 | 0.099632 | -0.155790 | 0.213591 |
plot_queries_results(WEAT_gender_results_agg).show()
It is also possible to ask the function to return only the aggregated
results using the parameter return_only_aggregation
WEAT_gender_results_only_agg = run_queries(
WEAT,
gender_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
aggregate_results=True,
aggregation_function="abs_avg",
return_only_aggregation=True,
queries_set_name="Gender Queries",
)
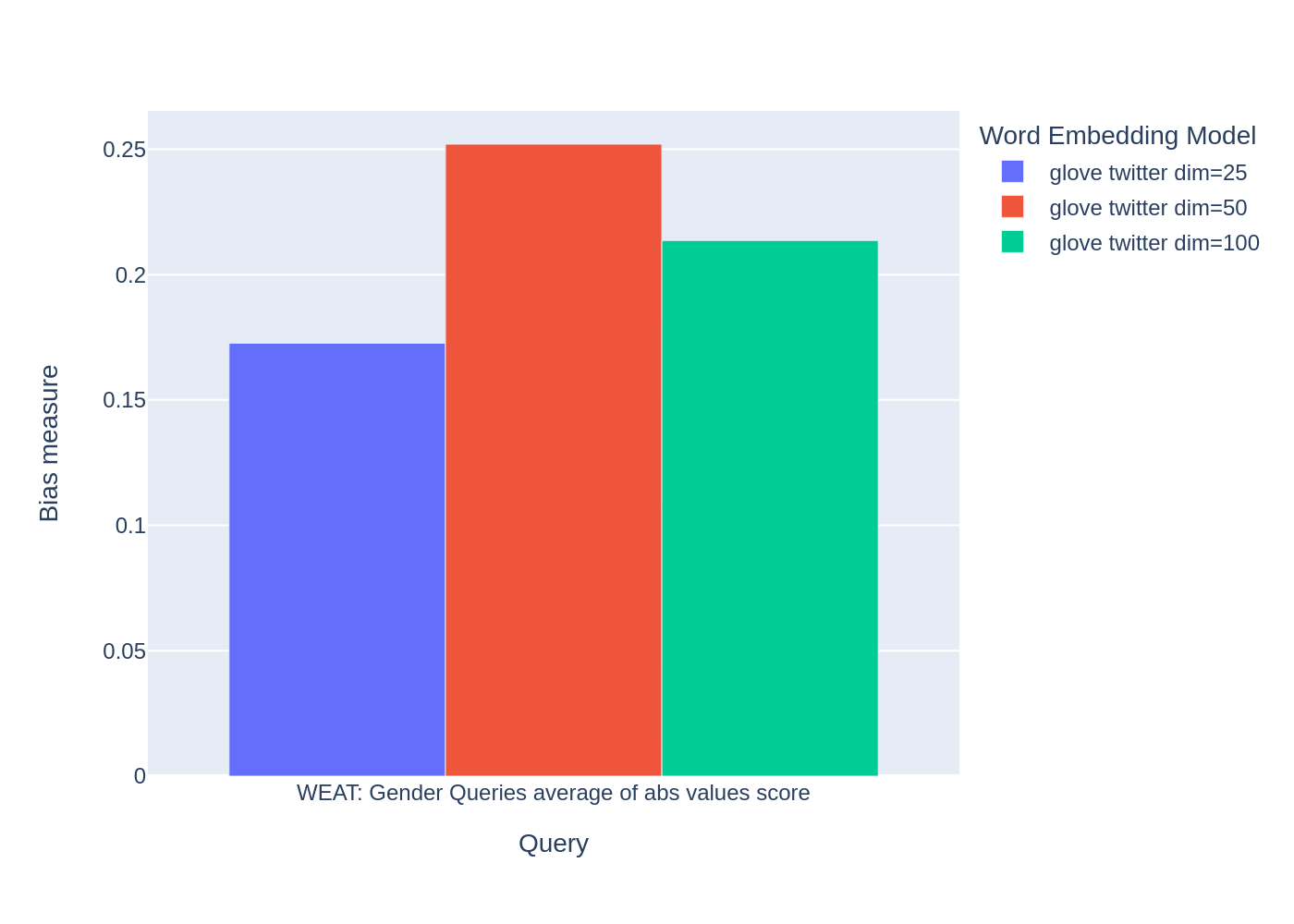
WEAT_gender_results_only_agg
| WEAT: Gender Queries average of abs values score | |
|---|---|
| model_name | |
| glove twitter dim=25 | 0.172642 |
| glove twitter dim=50 | 0.252007 |
| glove twitter dim=100 | 0.213591 |
fig = plot_queries_results(WEAT_gender_results_only_agg)
fig.show()
Model Ranking
It may be desirable to obtain an overall view of the bias by model using different metrics or bias criteria. While the aggregate values can be compared directly, two problems are likely to be encountered:
One type of bias criterion can dominate the other because of significant differences in magnitude.
Different metrics can operate on different scales, which makes them difficult to compare.
To show these problems, suppose we have:
Two sets of queries: one that explores gender biases and another that explores ethnicity biases.
Three
Glovemodels of 25, 50 and 100 dimensions trained on the same twitter dataset.
Then we run run_queries() on this set of model-queries using
WEAT, and to corroborate the results obtained, we also use
Relative Negative Sentiment Bias (RNSB).
The first problem occurs when the bias scores obtained from one set of queries are much higher than those from the other set, even when the same metric is used.
When executing run_queries() with the gender and ethnicity queries on
the models described above, the results obtained are as follows:
model_name |
WEAT: Gender Queries average of abs values score |
WEAT: Ethnicity Queries average of abs values score |
|---|---|---|
glove twitter dim=25 |
0.210556 |
2.64632 |
glove twitter dim=50 |
0.292373 |
1.87431 |
glove twitter dim=100 |
0.225116 |
1.78469 |
As can be seen, the results of ethnicity bias are much greater than those of gender.
The second problem is when different metrics return results on different scales of magnitude.
When executing run_queries() with the gender queries and models
described above using both WEAT and RNSB, the results obtained are as
follows:
model_name |
WEAT: Gender Queries average of abs values score |
RNSB: Gender Queries average of abs values score |
|---|---|---|
glove twitter dim=25 |
0.210556 |
0.032673 |
glove twitter dim=50 |
0.292373 |
0.049429 |
glove twitter dim=100 |
0.225116 |
0.0312772 |
We can see differences between the results of both metrics of an order of magnitude.
One solution to this problem is to create rankings. Rankings focus on the relative differences reported by the metrics (for different models) instead of focusing on the absolute values.
The following guide show how to create rankings that evaluate gender bias and ethnicity.
Gender Bias Model Ranking
# define the queries
gender_query_1 = Query(
[word_sets["male_terms"], word_sets["female_terms"]],
[word_sets["career"], word_sets["family"]],
["Male terms", "Female terms"],
["Career", "Family"],
)
gender_query_2 = Query(
[word_sets["male_terms"], word_sets["female_terms"]],
[word_sets["science"], word_sets["arts"]],
["Male terms", "Female terms"],
["Science", "Arts"],
)
gender_query_3 = Query(
[word_sets["male_terms"], word_sets["female_terms"]],
[word_sets["math"], word_sets["arts_2"]],
["Male terms", "Female terms"],
["Math", "Arts"],
)
gender_queries = [gender_query_1, gender_query_2, gender_query_3]
# run the queries using WEAT
WEAT_gender_results = run_queries(
WEAT,
gender_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
aggregate_results=True,
return_only_aggregation=True,
queries_set_name="Gender Queries",
)
# run the queries using WEAT effect size
WEAT_EZ_gender_results = run_queries(
WEAT,
gender_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}], "return_effect_size": True,},
aggregate_results=True,
return_only_aggregation=True,
queries_set_name="Gender Queries",
)
# run the queries using RNSB
RNSB_gender_results = run_queries(
RNSB,
gender_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
aggregate_results=True,
return_only_aggregation=True,
queries_set_name="Gender Queries",
)
The rankings can be calculated by means of the create_ranking()
function. This function receives as input results from running
run_queries() and assumes that the last column contains the aggregated
values.
from wefe.utils import create_ranking
# create the ranking
gender_ranking = create_ranking(
[WEAT_gender_results, WEAT_EZ_gender_results, RNSB_gender_results]
)
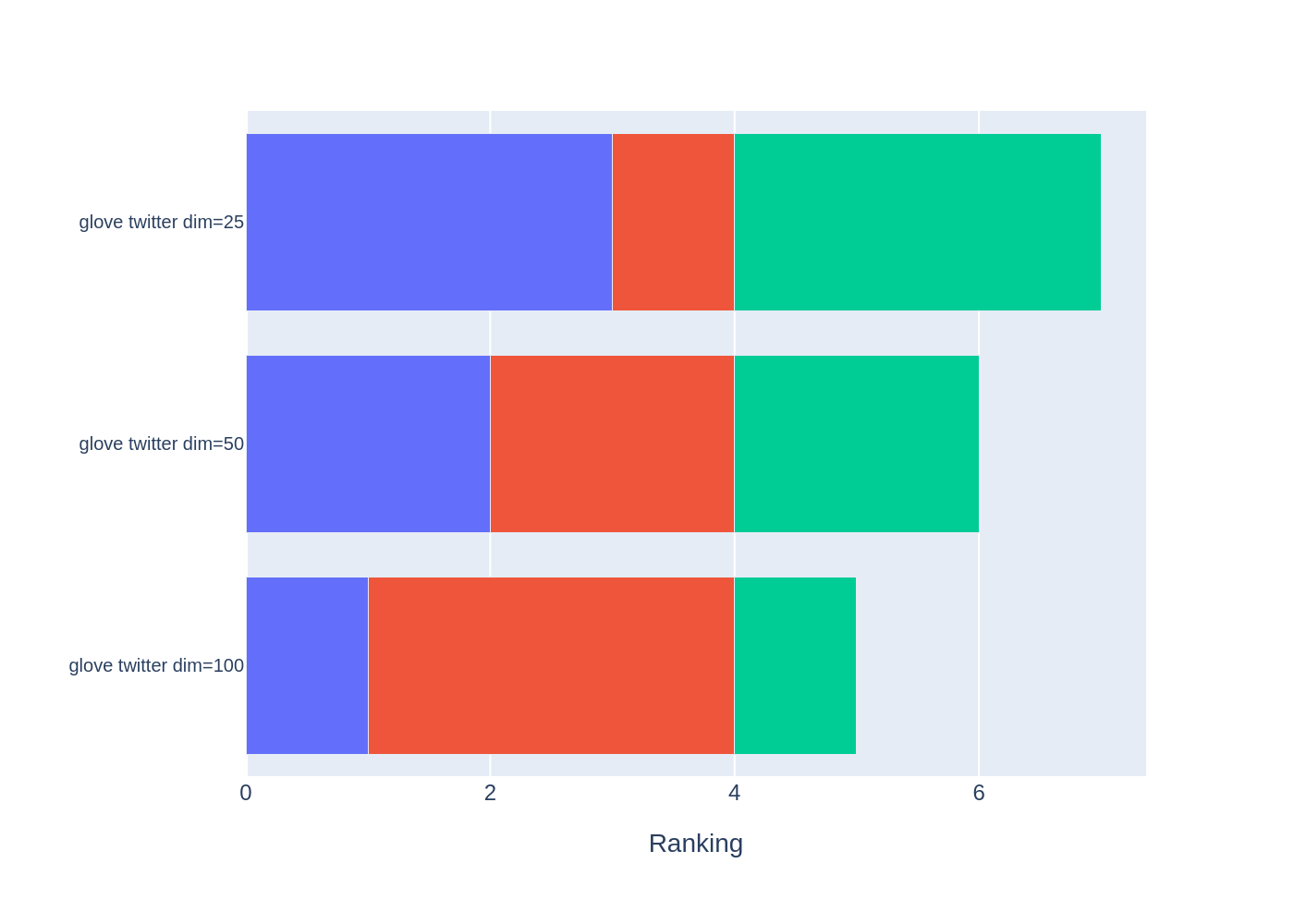
gender_ranking
| WEAT: Gender Queries average of abs values score (1) | WEAT: Gender Queries average of abs values score (2) | RNSB: Gender Queries average of abs values score | |
|---|---|---|---|
| model_name | |||
| glove twitter dim=25 | 1.0 | 1.0 | 3.0 |
| glove twitter dim=50 | 3.0 | 2.0 | 1.0 |
| glove twitter dim=100 | 2.0 | 3.0 | 2.0 |
Ethnicity Bias Model Ranking
# define the queries
ethnicity_query_1 = Query(
[word_sets["european_american_names_5"], word_sets["african_american_names_5"]],
[word_sets["pleasant_5"], word_sets["unpleasant_5a"]],
["European Names", "African Names"],
["Pleasant", "Unpleasant"],
)
ethnicity_query_2 = Query(
[word_sets["european_american_names_7"], word_sets["african_american_names_7"]],
[word_sets["pleasant_9"], word_sets["unpleasant_9"]],
["European Names", "African Names"],
["Pleasant 2", "Unpleasant 2"],
)
ethnicity_queries = [ethnicity_query_1, ethnicity_query_2]
# run the queries using WEAT
WEAT_ethnicity_results = run_queries(
WEAT,
ethnicity_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
aggregate_results=True,
return_only_aggregation=True,
queries_set_name="Ethnicity Queries",
)
# run the queries using WEAT effect size
WEAT_EZ_ethnicity_results = run_queries(
WEAT,
ethnicity_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}], "return_effect_size": True,},
aggregate_results=True,
return_only_aggregation=True,
queries_set_name="Ethnicity Queries",
)
# run the queries using RNSB
RNSB_ethnicity_results = run_queries(
RNSB,
ethnicity_queries,
models,
metric_params={"preprocessors": [{"lowercase": True}]},
aggregate_results=True,
return_only_aggregation=True,
queries_set_name="Ethnicity Queries",
)
# create the ranking
ethnicity_ranking = create_ranking(
[WEAT_ethnicity_results, WEAT_EZ_gender_results, RNSB_ethnicity_results]
)
ethnicity_ranking
| WEAT: Ethnicity Queries average of abs values score | WEAT: Gender Queries average of abs values score | RNSB: Ethnicity Queries average of abs values score | |
|---|---|---|---|
| model_name | |||
| glove twitter dim=25 | 3.0 | 1.0 | 3.0 |
| glove twitter dim=50 | 2.0 | 2.0 | 2.0 |
| glove twitter dim=100 | 1.0 | 3.0 | 1.0 |
Plotting the rankings
It is possible to graph the rankings in barplots using the
plot_ranking() function. The generated figure shows the accumulated
rankings for each embedding model. Each bar represents the sum of the
rankings obtained by each embedding. Each color within a bar represents
a different criterion-metric ranking.
from wefe.utils import plot_ranking
fig = plot_ranking(gender_ranking)
fig.show()
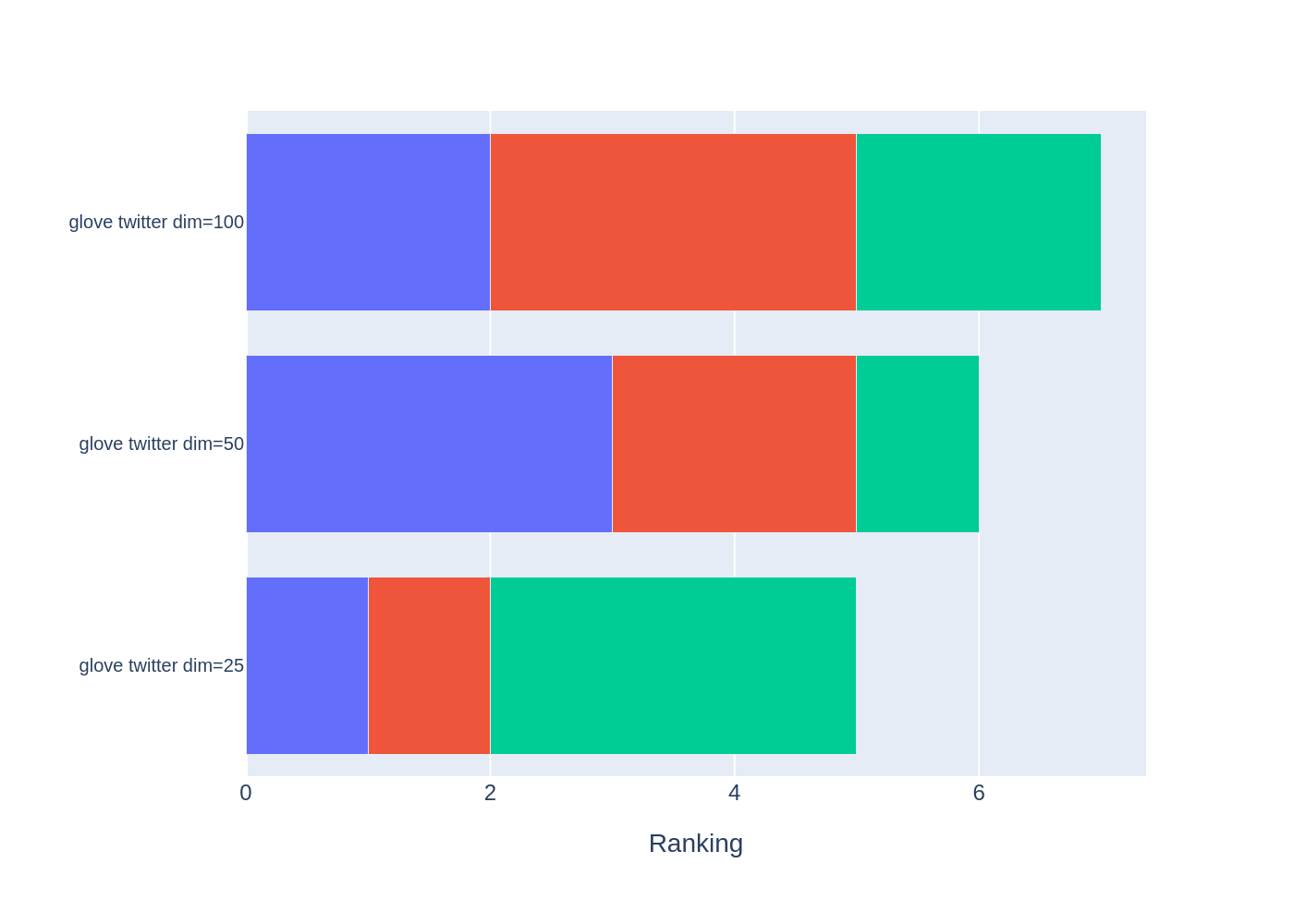
fig = plot_ranking(ethnicity_ranking)
fig.show()
Correlating Rankings
Having obtained rankings by metric for each embeddings, it would be ideal to see and analyze the degree of agreement between them.
A high concordance between the rankings allows us to state with some certainty that all metrics evaluated the embedding models in a similar way and therefore, that the ordering of embeddings by bias calculated makes sense. On the other hand, a low degree of agreement shows the opposite: the rankings do not allow to clearly establish which embedding is less biased than another.
The level of concordance of the rankings can be evaluated by calculating
correlations.WEFE provides calculate_ranking_correlations() to
calculate the correlations between rankings.
from wefe.utils import calculate_ranking_correlations, plot_ranking_correlations
correlations = calculate_ranking_correlations(gender_ranking)
correlations
| WEAT: Gender Queries average of abs values score (1) | WEAT: Gender Queries average of abs values score (2) | RNSB: Gender Queries average of abs values score | |
|---|---|---|---|
| WEAT: Gender Queries average of abs values score (1) | 1.0 | 0.5 | -1.0 |
| WEAT: Gender Queries average of abs values score (2) | 0.5 | 1.0 | -0.5 |
| RNSB: Gender Queries average of abs values score | -1.0 | -0.5 | 1.0 |
Note
calculate_ranking_correlations uses the corr() pandas
dataframe method. The type of correlation that is calculated can be changed
through the method parameter. The available options are:
'pearson', 'spearman', 'kendall'. By default, the spearman
correlation is calculated.
In this example, Kendall’s correlation is used.
calculate_ranking_correlations(gender_ranking, method="kendall")
| WEAT: Gender Queries average of abs values score (1) | WEAT: Gender Queries average of abs values score (2) | RNSB: Gender Queries average of abs values score | |
|---|---|---|---|
| WEAT: Gender Queries average of abs values score (1) | 1.000000 | 0.333333 | -1.000000 |
| WEAT: Gender Queries average of abs values score (2) | 0.333333 | 1.000000 | -0.333333 |
| RNSB: Gender Queries average of abs values score | -1.000000 | -0.333333 | 1.000000 |
WEFE also provides a function for graphing the correlations:
correlation_fig = plot_ranking_correlations(correlations)
correlation_fig.show()
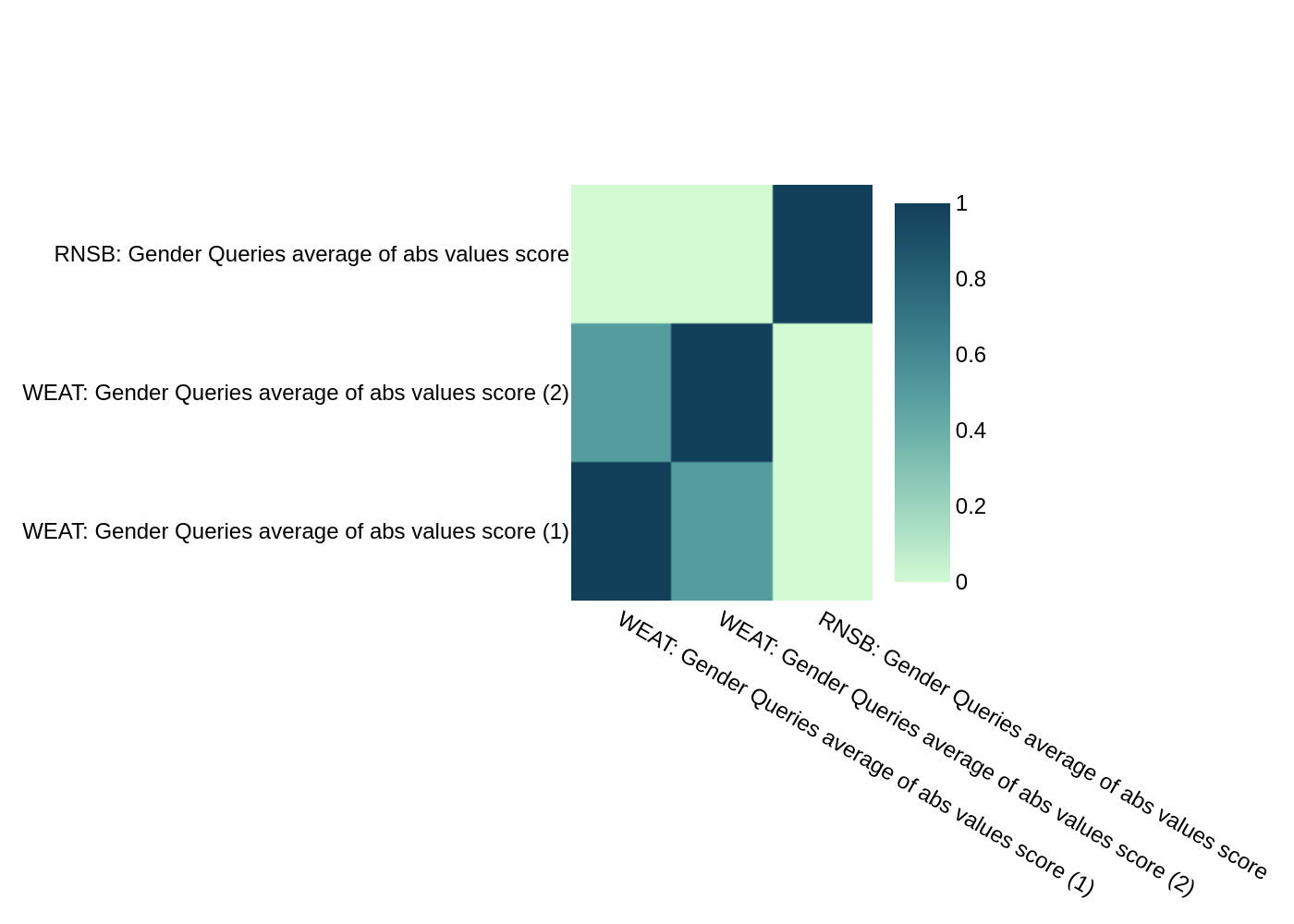
In this case, only two of the three rankings show similar results.