About¶
Word Embedding Fairness Evaluation (WEFE) is an open source library for measuring bias in word embedding models. It generalizes many existing fairness metrics into a unified framework and provides a standard interface for:
Encapsulating existing fairness metrics from previous work and designing new ones.
Encapsulating the test words used by fairness metrics into standard objects called queries.
Computing a fairness metric on a given pre-trained word embedding model using user-given queries.
It also provides more advanced features for:
Running several queries on multiple embedding models and returning a DataFrame with the results.
Plotting those results on a barplot.
Based on the above results, calculating a bias ranking for all embedding models. This allows the user to evaluate the fairness of the embedding models according to the bias criterion (defined by the query) and the metric used.
Plotting the ranking on a barplot.
Correlating the rankings. This allows the user to see how the rankings of the different metrics or evaluation criteria are correlated with respect to the bias presented by the models.
Motivation and objectives¶
Word Embeddings models are a core component in almost all NLP systems. Several studies has shown that they are prone to inherit stereotypical social biases from the corpus they were built on. The common method for quantifying bias is to use a metric that calculates the relationship between sets of word embeddings representing different social groups and attributes.
Although previous studies have begun to measure bias in embeddings, they are limited both in the types of bias measured (gender, ethnic) and in the models tested. Moreover, each study proposes its own metric, which makes the relationship between the results obtained unclear.
This fact led us to consider that we could use these metrics and studies to make a case study in which we compare and rank the embedding models according to their bias.
In order to address the above, we first proposed WEFE as a theoretical framework that aims to formalize the main building blocks for measuring bias in word embedding models. Then, the need to conduct our case study led to the implementation of WEFE in code. Seeing the possibility that other research teams are facing the same problem, we decided to improve this code and publish it as a library, hoping that it can be useful for their studies.
The main objectives we want to achieve with this library are:
To provide a ready-to-use tool that allows the user to run bias tests in a straightforward manner.
To provide simple interface to develop new metrics.
To solve the two main problems that arise when comparing experiments based on different metrics:
Some metrics operate with different numbers of word sets as input.
The outputs of different metrics are incompatible with each other (their scales are different, some metrics return real numbers and others only positive ones, etc..)
The Framework¶
Here we present the main building blocks of the framework and then, we present the common usage pattern of WEFE.
Target set¶
A target word set (denoted by \(T\)) corresponds to a set of words intended to denote a particular social group,which is defined by a certain criterion. This criterion can be any character, trait or origin that distinguishes groups of people from each other e.g., gender, social class, age, and ethnicity. For example, if the criterion is gender we can use it to distinguish two groups, women and men. Then, a set of target words representing the social group “women” could contain words like “she”, “woman”, “girl”, etc. Analogously a set of target words the representing the social group “men” could include “he”, “man”, “boy”, etc.
Attribute set¶
An attribute word set (denoted by \(A\)) is a set of words representing some attitude, characteristic, trait, occupational field, etc. that can be associated with individuals from any social group. For example, the set of science attribute words could contain words such as “technology”, “physics”, “chemistry”, while the art attribute words could have words like “poetry”, “dance”, “literature”.
Query¶
Queries are the main building blocks used by fairness metrics to measure bias of word embedding models. Formally, a query is a pair \(Q=(\mathcal{T},\mathcal{A})\) in which \(T\) is a set of target word sets, and \(A\) is a set of attribute word sets. For example, consider the target word sets:
and the attribute word sets
Then the following is a query in our framework
When a set of queries \(\mathcal{Q} = {Q_1, Q_2, \dots, Q_n}\) is intended to measure a single type of bias, we say that the set has a Bias Criterion. Examples of bias criteria are gender, ethnicity, religion, politics, social class, among others.
Warning
To accurately study the biases contained in word embeddings, queries may contain words that could be offensive to certain groups or individuals. The relationships studied between these words DO NOT represent the ideas, thoughts or beliefs of the authors of this library. This applies to this and all pages of the documentation.
Query Template¶
A query template is simply a pair \((t,a)\in\mathbb{N}\times\mathbb{N}\). We say that query \(Q=(\mathcal{T},\mathcal{A})\) satisfies a template \((t,a)\) if \(|\mathcal{T}|=t\) and \(|\mathcal{A}|=a\).
Fairness Measure¶
A fairness metric is a function that quantifies the degree of association between target and attribute words in a word embedding model. In our framework, every fairness metric is defined as a function that has a query and a model as input, and produces a real number as output.
Several fairness metrics have been proposed in the literature. But not all of them share a common input template for queries. Thus, we assume that every fairness metric comes with a template that essentially defines the shape of the input queries supported by the metric.
Formally, let \(F\) be a fairness metric with template \(s_F=(t_F,a_F)\). Given an embedding model \(\mathbf{M}\) and a query \(Q\) that satisfies \(s_F\), the metric produces the value \(F(\mathbf{M},Q)\in \mathbb{R}\) that quantifies the degree of bias of \(\mathbf{M}\) with respect to query \(Q\).
Standard usage pattern of WEFE¶
The following flow chart shows how to perform a bias measurement using a gender query, word2vec embeddings and the WEAT metric.
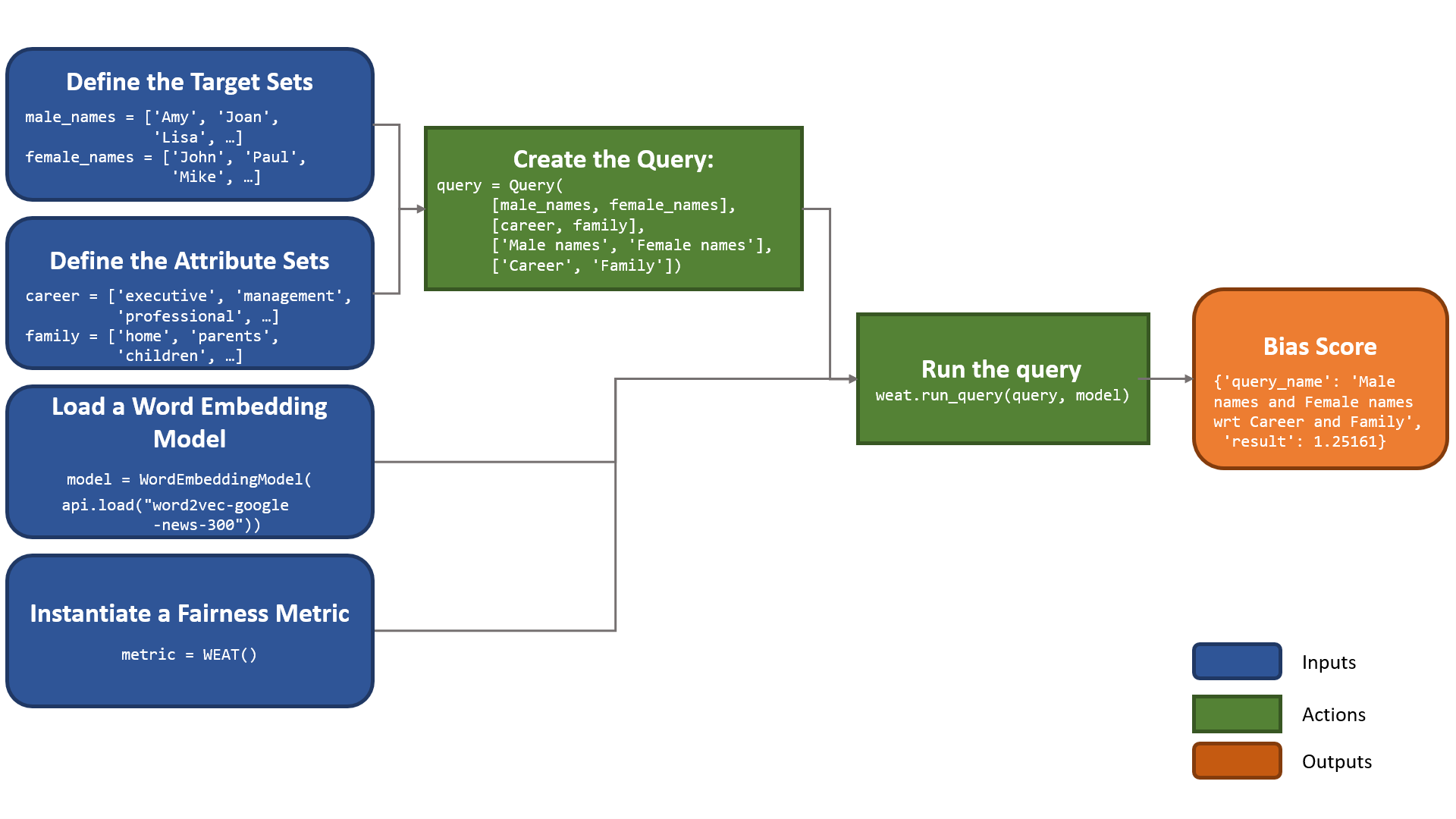
To see the implementation of this query using WEFE, refer to the Quick start section.
Metrics¶
The metrics implemented in the package so far are:
WEAT¶
Word Embedding Association Test (WEAT), presented in the paper “Semantics derived automatically from language corpora contain human-like biases”. This metric receives two sets \(T_1\) and \(T_2\) of target words, and two sets \(A_1\) and \(A_2\) of attribute words. Its objective is to quantify the strength of association of both pairs of sets through a permutation test. It also contains a variant, WEAT Effect Size. This variant represents a normalized measure that quantifies how far apart the two distributions of association between targets and attributes are.
RND¶
Relative Norm Distance (RND), presented in the paper “Word embeddings quantify 100 years of gender and ethnic stereotypes”. RND averages the embeddings of each target set, then for each of the attribute words, calculates the norm of the difference between the word and the average target, and then subtracts the norms. The more positive (negative) the relative distance from the norm, the more associated are the sets of attributes towards group two (one).
RNSB¶
Relative Negative Sentiment Bias (RNSB), presented in the paper “A transparent framework for evaluating unintended demographic bias in word embeddings”.
RNSB receives as input queries with two attribute sets \(A_1\) and \(A_2\) and two or more target sets, and thus has a template of the form \(s=(N,2)\) with \(N\geq 2\). Given a query \(Q=(\{T_1,T_2,\ldots,T_n\},\{A_1,A_2\})\) and an embedding model \(\mathbf{M}\), in order to compute the metric \(F_{\text{RNSB}}(\mathbf{M},Q)\) one first constructs a binary classifier \(C_{(A_1,A_2)}(\cdot)\) using set \(A_1\) as training examples for the negative class, and \(A_2\) as training examples for the positive class. After the training process, this classifier gives for every word \(w\) a probability \(C_{(A_1,A_2)}(w)\) that can be interpreted as the degree of association of \(w\) with respect to \(A_2\) (value \(1-C_{(A_1,A_2)}(w)\) is the degree of association with \(A_1\)). Now, we construct a probability distribution \(P(\cdot)\) over all the words \(w\) in \(T_1\cup \cdots \cup T_n\), by computing \(C_{(A_1,A_2)}(w)\) and normalizing it to ensure that \(\sum_w P(w)=1\). The main idea behind RNSB is that the more that \(P(\cdot)\) resembles a uniform distribution, the less biased the word embedding model is.
MAC¶
Mean Average Cosine Similarity (MAC), presented in the paper “Black is to criminals caucasian is to police: Detecting and removing multiclass bias in word embeddings”.
ECT¶
The Embedding Coherence Test, presented in “Attenuating Bias in Word vectors” calculates the average target group vectors, measures the cosine similarity of each to a list of attribute words and calculates the correlation of the resulting similarity lists.
RIPA —
The Relational Inner Product Association, presented in the paper “Understanding Undesirable Word Embedding Associations”, calculates bias by measuring the bias of a term by using the relation vector (i.e the first principal component of a pair of words that define the association) and calculating the dot product of this vector with the attribute word vector. RIPA’s advantages are its interpretability, and its relative robustness compared to WEAT with regard to how the relation vector is defined.
Changelog¶
Renamed optional
run_queryparameterwarn_filtered_wordsto warn_not_found_words.Added
word_preprocessor_argsparameter torun_querythat allows to specify transformations prior to searching for words in word embeddings.Added
secondary_preprocessor_argsparameter torun_querywhich allows to specify a second pre-processor transformation to words before searching them in word embeddings. It is not necessary to specify the first preprocessor to use this one.Implemented
__getitem__function inWordEmbeddingModel. This method allows to obtain an embedding from a word from the model stored in the instance using indexers.Removed underscore from class and instance variable names.
Improved type and verification exception messages when creating objects and executing methods.
Fix an error that appeared when calculating rankings with two columns of aggregations with the same name.
Ranking correlations are now calculated using pandas
corrmethod.Changed metric template, name and short_names to class variables.
Implemented
random_statein RNSB to allow replication of the experiments.run_query now returns as a result the default metric requested in the parameters and all calculated values that may be useful in the other variables of the dictionary.
Fixed problem with api documentation: now it shows methods of the classes.
Implemented p-value for WEAT
Relevant Papers¶
The intention of this section is to provide a list of the works on which WEFE relies as well as a rough reference of works on measuring and mitigating bias in word embeddings.
Measurements and Case Studies¶
Bias Mitigation¶
Surveys and other resources¶
A Survey on Bias and Fairness in Machine Learning
Bakarov, A. (2018). A survey of word embeddings evaluation methods. arXiv preprint arXiv:1801.09536.
Bias in Contextualized Word Embeddings
Citation¶
Please cite the following paper if using this package in an academic publication:
P. Badilla, F. Bravo-Marquez, and J. Pérez WEFE: The Word Embeddings Fairness Evaluation Framework In Proceedings of the 29th International Joint Conference on Artificial Intelligence and the 17th Pacific Rim International Conference on Artificial Intelligence (IJCAI-PRICAI 2020), Yokohama, Japan.
The author version can be found at the following link.
Bibtex:
@InProceedings{wefe2020,
title = {WEFE: The Word Embeddings Fairness Evaluation Framework},
author = {Badilla, Pablo and Bravo-Marquez, Felipe and Pérez, Jorge},
booktitle = {Proceedings of the Twenty-Ninth International Joint Conference on
Artificial Intelligence, {IJCAI-20}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
pages = {430--436},
year = {2020},
month = {7},
doi = {10.24963/ijcai.2020/60},
url = {https://doi.org/10.24963/ijcai.2020/60},
}
Roadmap¶
We expect in the future to:
Implement the metrics that have come out in the last works about bias in embeddings.
Implement new queries on different criteria.
Create a single script that evaluates different embedding models under different bias criteria.
From the previous script, rank as many embeddings available on the web as possible.
Implement a de-bias module.
Implement a visualization module.
Implement p-values with statistic resampling to all metrics.
Licence¶
WEFE is licensed under the BSD 3-Clause License.
Details of the license on this link.
Team¶
Pablo Badilla
Thank you very much to all our contributors!
Contact¶
Please write to pablo.badilla at ug.chile.cl for inquiries about the software. You are also welcome to do a pull request or publish an issue in the WEFE repository on Github.
Acknowledgments¶
This work was funded by the Millennium Institute for Foundational Research on Data (IMFD).